高德网络定位之“移动WiFi识别”
导读
随着时代的发展,近10年来位置产业蓬勃发展,定位能力逐渐从低精度走向高精度,从部分场景走向泛在定位。设备和场景的丰富,使得定位技术和能力也不断的优化更新。定位能力包括GNSS、DR(航迹推算)、MM(地图匹配)、视觉定位和网络定位等。
其中网络定位是通过客户端扫描到的WiFi和基站信息来进行定位的一种定位方式。网络定位能力是GNSS定位的有力补充,在GNSS无法定位或者定位较慢的时候,网络定位都可以快速给出位置。网络定位能力也是高德能够深植于各类手机厂商(提供系统级网络定位能力)和APP(出行、社交、O2O、P2P、旅游、新闻、天气等诸多领域)的原因之一。
要做到通过WiFi和基站来定位,我们需要通过亿级数据来挖掘出WiFi和基站的类型、位置、指纹等各种信息。这些信息的挖掘,历史上是通过一系列的人工经验策略来进行的,人工规则的历史局限带来了所挖掘信息较低的准召率,为了进一步提升高德网络定位能力,我们需要卸下以往的包袱,从方法上进行改变。
如何定义“网络定位”
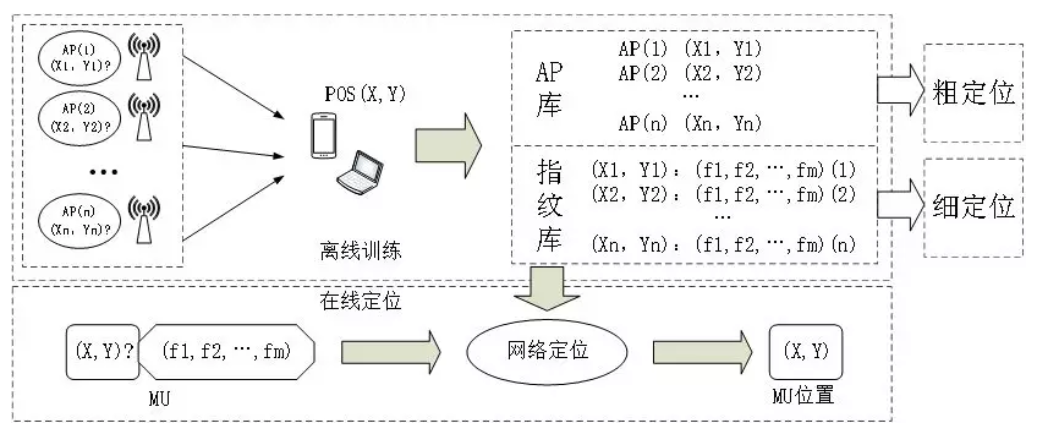
网络定位分为离线训练和在线定位两个过程:
离线训练:是在用户有GPS位置时采集周边的WiFi和基站(以下统称为AP)信息,通过对采集数据进行聚类和关联,得到两类数据产品:AP库和指纹库;
在线定位:与离线训练的过程正好相反,当用户没有GPS定位时,可以通过扫描到的周边WiFi和基站信号,结合离线训练出的AP库和指纹库来进行实时定位。
AP库和指纹库这两类数据产品中:
指纹库:以物理坐标位置对应的特征指纹信息为内容,这些特征指纹信息可以包括扫描到的WiFi或者基站的信号强度分布,采集点频次等统计信息,也可以是通过神经网络提取出的特征信息。
AP库:以WiFi的mac地址或者基站的ID(gsm基站为mcc_mnc_lac_cid,cdma基站为mcc_sid _bsid_nid )为主键,以WiFi或者基站的物理坐标信息(经纬度或者地理栅格坐标信息)为内容。
典型的AP库数据只包含挖掘出的物理坐标信息和覆盖半径,这种“点圆模型”是对AP发射信号的一种理想化,没有考虑任何实际场景中的信号遮挡、反射等情况,所以AP库大多用来进行粗略定位。而指纹库直接与位置相关,可以刻画比“点圆模型”更细致的分布信息,所以指纹库可以用来进行精细定位。
高德的指纹库主要包括特有的室内指纹和全场景指纹信息两种。
网络定位的问题
网络定位的基本思路类似聚类,假设用户手机扫描到的AP列表中的AP的位置均比较固定,则我们可以以这些AP位置为锚点,来确定用户位置。现实世界中,锚点(即AP库中的AP)的位置通过大数据来进行挖掘,并不一定完全准确,甚至出现严重错误。
针对WiFi而言,移动WiFi、克隆WiFi、搬家WiFi等都可能造成AP位置的错误。移动WiFi包含手机热点,4g移动路由器,公交车/地铁/高铁上的WiFi热点等,这些WiFi的移动属性较强,位置频繁变化,如下图所示。
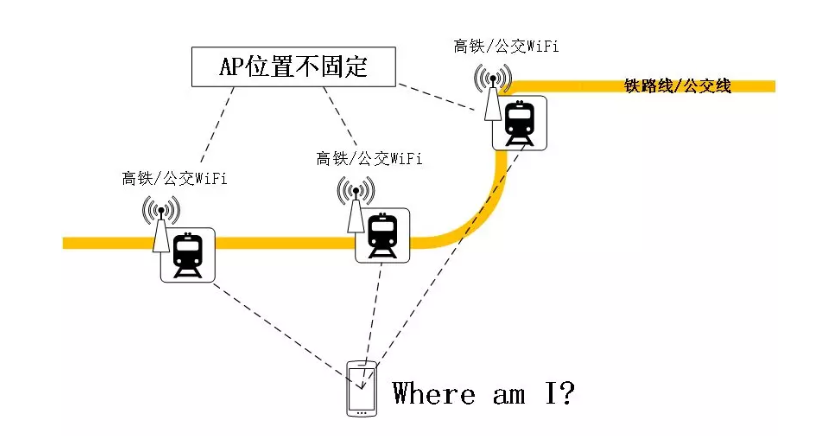
如果以移动WiFi作为锚点,因为这些锚点的位置不固定,极可能会导致用户的定位出现极大误差。克隆WiFi指不同的WiFi设备使用了同一个mac地址,国内的腾达和斐讯等路由器厂商制造了大量这样的WiFi设备(例如大部分mac前缀为“c8:3a:35”的即为腾达的克隆WiFi),克隆WiFi导致AP库中同一个mac地址对应的锚点位置有多个。搬家WiFi指某些因为搬家而发生位置变化的WiFi,数据挖掘存在一定的滞后性,搬家后AP库中的位置未及时更新,也会造成定位错误。
因为大误差的badcase严重损害用户体验,我们必须要将这些非固定WiFi的属性在AP库中标记出来。
历史上,高德是通过一系列简单的人工规则对这些WiFi的属性进行分类的。例如,通过采集点覆盖范围较大来判定移动WiFi,通过mac前缀来判定克隆WiFi等。人工规则的缺点是准召率不高,训练分类模型就成了一个自然的选择。
鉴于badcase中最严重的问题是移动WiFi的准召率不高,下面我们就尝试使用监督学习的方法来进行“移动WiFi识别”。
如何实现“移动Wifi识别”
样本提取
AP库中的WiFi数量十分庞大,如果我们在AP库中随机抽取样本进行人工标注,那大部分标注的结果可能是人工规则判定正确的样本,为了尽可能低成本获取有效的标注样本,我们借鉴主动学习的思路,不断抽取模糊样本进行标注,快速迭代使得模型稳定。
我们根据人工规则的判定结果提取了一批确定性较高的样本,使用人工强特征训练第一版模型,之后将第一版模型的预测结果与线上人工规则的结果进行全量比较,提取出模糊样本进行人工标注。在标注样本的过程中发现问题,持续特征工程,不断迭代模型。
这里模糊样本的定义包含三种:预测结果与上一版模型的结果不同,预测概率值在0.5附近,预测结果在不同训练周期内存在波动(例如昨天识别是移动WiFi,今天识别是非移动)。
特征提取
移动WiFi vs 克隆/搬家WiFi:
第一版模型中,我们使用了一些采集聚集程度相关的特征。

模型迭代过程中,我们遇到的第一个问题是移动WiFi与克隆WiFi或搬家WiFi比较容易混淆。下面几幅图分别画出了固定WiFi、移动WiFi、克隆WiFi、搬家WiFi的定位点散布的实例。
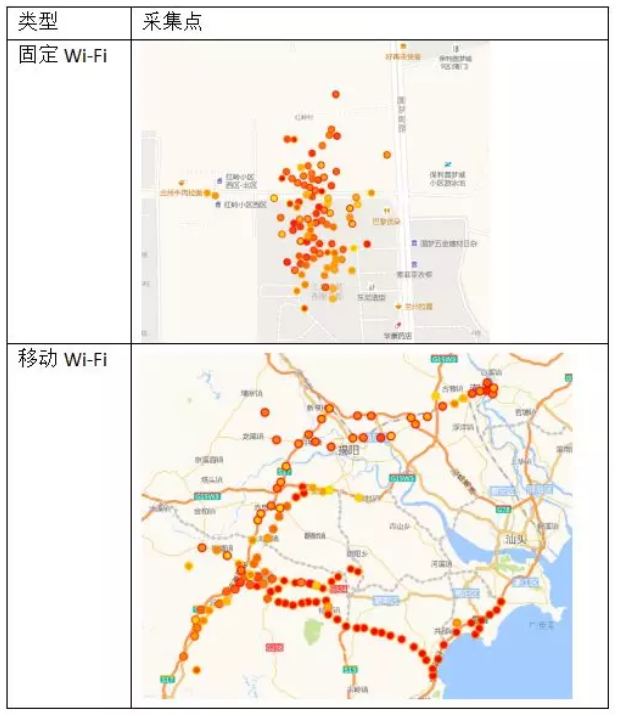
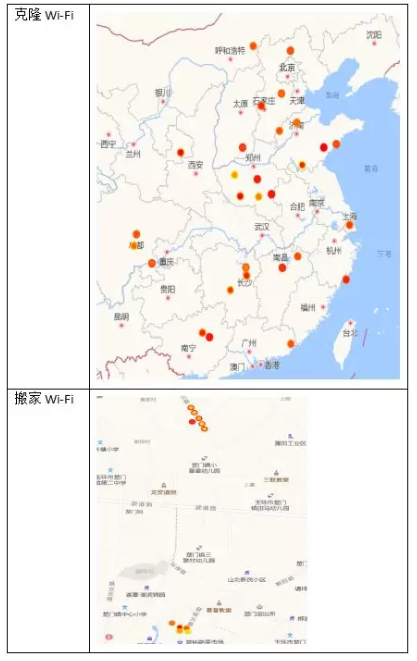
可以看到,如果仅仅使用定位点的聚集程度来分类,那克隆WiFi和搬家WiFi的定位点也比较分散,极易与移动WiFi混淆。所以我们先使用聚簇算法,将采集点局部聚集的点集合成不同的簇,在每个簇中计算定位点的散布程度,再将所有簇的散布程度求平均值等,获取平均意义上的聚集程度。
多维度提取特征:
为了进一步提升分类的准召率,我们不仅从定位点的聚集维度来提取特征,还增加了信号强度、关联特征、IP特征、时间特征等,以下进行简要介绍:
信号强度信息:(和上节中的聚集特征一起,统称为采集特征)移动设备与非移动设备采集点的信号强度在去除设备差异性之后,分布存在差异性。
关联特征:关联信息是指当设备扫描到的一次WiFi列表中,列表中所有WiFi两两之间就算产生了一次关联(或称邻居)关系,统计WiFi周边关联的WiFi和基站信息,可以描述出WiFi的移动属性。
IP特征:固网IP和移动网的IP存在一定隔离,移动WiFi设备的上游一般是通过基站连接的移动网,固定WiFi设备的上游一般是通过ADSL等连接的固网。
时间特征:固定WiFi一般是长时间连接电源的,而移动WiFi一般是临时在某些地方和时间短暂出现的。
聚合特征:
在AP库中,存在一部分WiFi定位信息不够充分,即使是人工标注也存在着非常大的不确定性,这些定位信息不够充分的WiFi,我们称之为“弱信息WiFi”。
对于这类WiFi,我们只有通过ssid和mac前缀来进行辅助判断。因为ssid中包含了一些诸如“iPhone”、“个人热点”、“oppo”、“shouqiyueche”(首汽约车)、“往返免费”、“tp-link”等能够表明设备属性的信息。另一方面,mac前缀(mac信息的前半部分)代表了厂商信息。基于这些辅助信息,我们可以在其他信息不够充分的情况下辅助推测WiFi的类别属性。
我们将基础特征(采集特征、关联特征、IP特征、时间特征)中较为重要的TOP_N维特征按照ssid和mac前缀进行聚合,聚合函数为中位数(median)和总体标准差(stddev)。这样,聚合特征体现了一类WiFi共有的特征,针对弱信息WiFi,我们就可以通过集体的特征来推测出个体的属性。
应用场景
除了提升网络定位能力,移动WiFi的识别还有更多用武之地,例如手机热点的识别,室内外的判断,建筑物和POI级别的定位等等。其中一个例子就是判断当前设备所连接的WiFi是否为移动热点(如4g路由器,手机热点等),在视频类的APP中,可以通过判别当前用户连接的WiFi是否为移动热点,从而控制是否进行视频的自动播放或缓存,给予用户提示性信息。
小结
最终我们使用随机森林来训练分类模型,经过特征选择和模型参数调整之后,最终得到的模型,移动WiFi的准召率均优于99.8%。高德网络定位的精度也因此得到了较大提升,尾部大误差badcase降低了18%左右。
网络定位作为一种低功耗的定位手段,不仅在GNSS无法触达的地区(例如地铁、室内等场景)为普通用户带来辅助的定位信息,而且在某些急救和寻人的场景中发挥了重要的作用。未来,随着5G通信技术的开展,将迎来更加精准的网络定位能力。