通信协议、计算机七层/四层模型、编解码序列化、外设、MCU知识总结
七层/四层模型
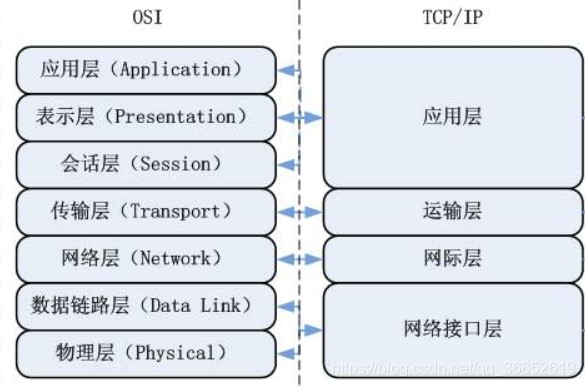
七层/四层模型详见:
https://www.atdevin.com/4265.html
https://www.atdevin.com/5382.html
https://www.atdevin.com/6614.html
TCP/IP协议各层作用
| 协议层 | 关键元素 | 作用 |
|---|---|---|
| 数据链路层 | MAC地址 | 依靠MAC地址,构建同子网主机到主机的数据包传输链路 |
| 网络层 | IP地址 | 依靠IP地址,构建源子网到目标子网的数据包传输链路 |
| 传输层 | 端口 | 依靠端口,构建源进程到目标进程的传输链路 |
| 应用层 | 应用自定义规则 | 依靠客户端与服务端共同定义的规则完成客户端与服务端的交互 |
详见:https://blog.csdn.net/weixin_33804582/article/details/85979643
TCP/IP五层对应的数据单元
比四层模型,多算一个物理层)
- 应用层:传输数据单元PDU
- 运输层:运输层的报文
- 网络层:IP数据报(IP分组)
- 数据链路层:(数据帧)(段加上ip地址称作数据包,数据包加上MAC地址称作数据帧)
- 物理层:01010101011101101010101
TCP/IP五层发送数据过程
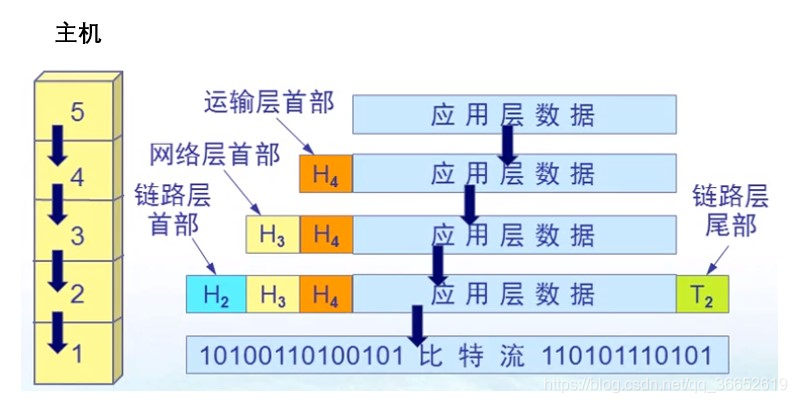
TCP/IP接收发送数据过程
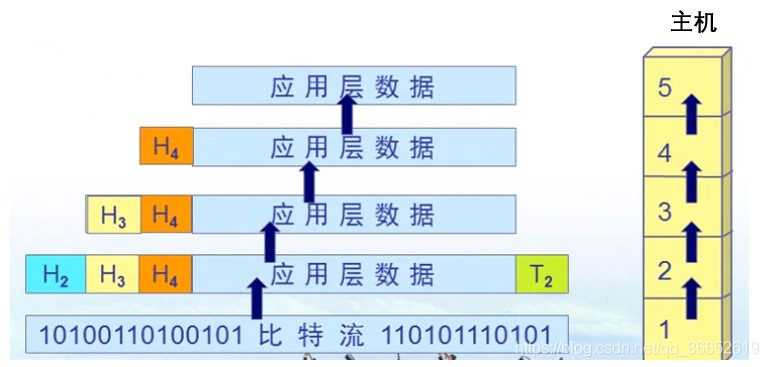
详见:https://www.atdevin.com/4265.html
计算机信息处理过程
假设被处理的信息是一串文本,并需要从一台设备传输到另外一台设备,并显示。
1.序列化,把文本编码成计算机可处理的二级制
2.各层协议的处理,比如经过http->TCP->IP,经过各层协议处理。
3.可能还有从cpu/mcu的RAM中保存ROM中之类的处理。
4.传输到另外一台计算机
5.各层协议的的反向操作,把各层协议头信息剥离后,形成内容
6.内容解码,机器理解的二进制转化成文本
7.GUI显示(渲染之类的)
不管是哪一层的协议,计算机放到内存(buf)里面的都是0101二进制的东西,因此信息的处理首先是序列化成二进制,然后是他通过Http、TCP、IP等协议,一层一层添加协议头。
信息的显示,都是一层一层通过协议拆解出最后的信息体,然后反序列化出可读的文本。对于高级语言编程,序列化这个过程,对开发者是黑盒,但序列化是真实存在的。
序列化(字符集与字符编码)
定义
什么是序列化,通过Unicode、utf-8、ascii等编码方式,把信息转换成二进制的过程。
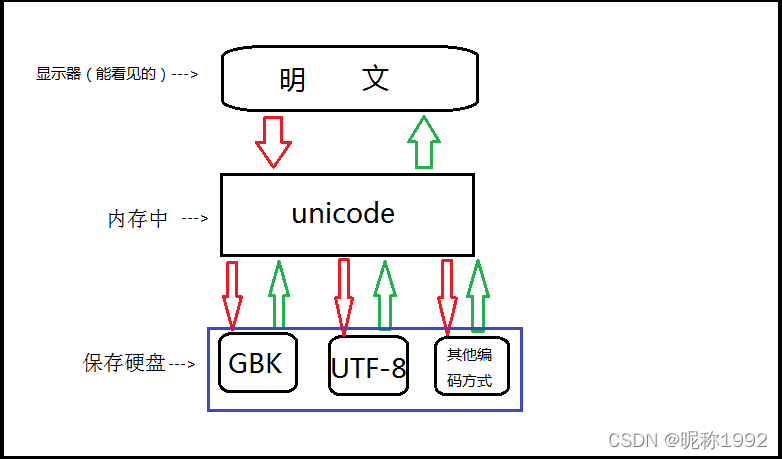
字符集就是字符的集合,如常见的 ASCII字符集,GB2312字符集,Unicode字符集等。这些不同字符集之间最大的区别是所包含的字符数量的不同。
字符编码则代表字符集的实际编码规则,是用于计算机解析字符的,如 GB2312,GBK,UTF-8 等。字符编码的本质就是如何使用二进制字节来表示字符的问题。
编码表,字符编码将人类的字符编码/转换成计算机能识别的数字,这种转换必须遵循一套固定的标准,该标准无非是人类字符与数字的对应关系,称之为字符编码表。
字符集和编码是一对多的关系,同一字符集可能有多种字符编码,如Unicode字符集就有 UTF-8,UTF-16 等。
常见字符编码简介
- bit:二进制位。
- Bytes:字节。
- ASCII码表:用1Bytes表示一个英文字符,1英文字符=8bit=1Bytes。
- GBK:用2Bytes表示一个中文字符,1Bytes去表示英文字符。
- unicode:内存中使用的是unicode编码,unicode把全世界的字符都建立好对应关系,用2Bytes去表示一个字符,比如,
0000 0000 0000 0000。 - utf-8:用1Bytes表示英文,用3Bytes表示中文。
字符编码需要记住的概念
- 内存中固定使用unicode编码,我们唯一可以改变的存储到硬盘时使用的编码
- 要想保证存取文件不乱码,应该保证文档当初是以什么编码格式存的,就应该以什么编码格式去读取
- python3解释器默认编码是UTF-8,python2解释器默认编码是ASCII
x='上' #如果文件头为coding:utf-8,那么"上"被存成utf-8格式的二进制 - 编码与解码
unicode——-编码encode——–>gbk
unicode<——-解码decode——–gbk
ascii编码
美国于上个世纪60年代制定了一套字符编码,英语字符与二进制位之间对应关系,做了统一规定。故此诞生了一直沿用至今的ASCII 码。
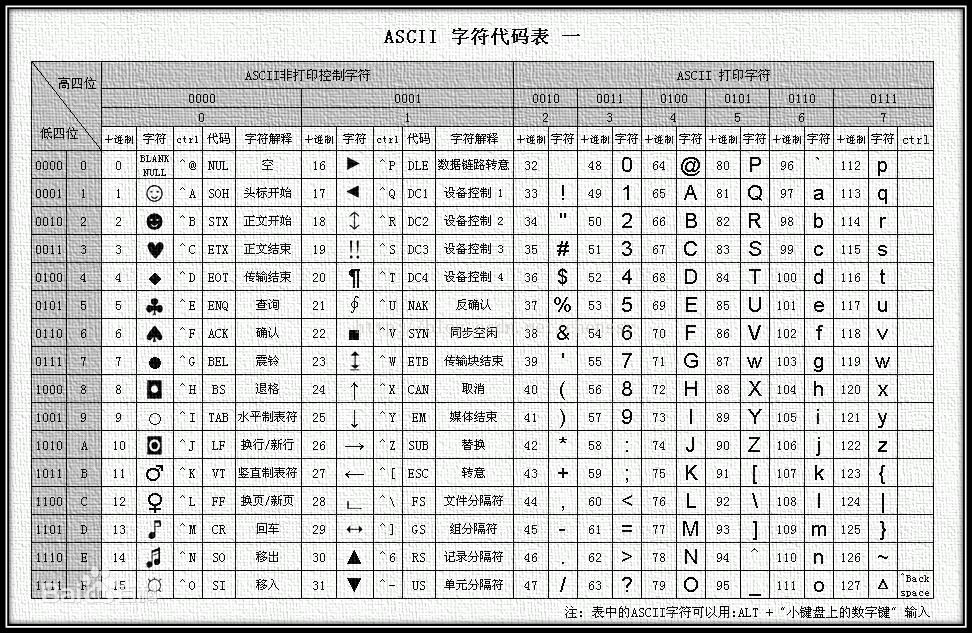
unicode编码
英语用128个符号编码就足够了,但是用来表示其他语言,128个符号是不够的。此时,unicode编码出现了。
unicode是这样一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码(在0-127位,unicode与ascii表示的字符相同)。
但是unicode编码存在另一个问题,例如:
- 字符A的unicode码是
\u0041,二进制标识为1000001. - 中文“一”的unicode码是
\u4E00,二进制表示为100111000000000 - 此时保存A需要一个字节,八位bit,保存“一”需要两个字节,16位bit,如何保存能让计算机知道几位bit代表一个字符?此时,utf-8出现了.
utf-8编码
utf-8编码解决的就是计算机中的字符保存的问题。
上述字符,“A”,“一”,如果都用两个字节表示,浪费资源,如果A用一个字节,“一”用两个字节,计算机无法字节识别(几位byte代表一个字符?)。
utf-8就是定义了一种计算机可以识别的用几位字节表示一个字符的方式。
utf-8定义:
1)对于单字节的符号,且第一位为0,后面7位为 Unicode 码. 因此对于英语字母,UTF-8 编码和 ASCII 码是相同的
2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
举例说明:
对于A来说,一个字节即可表示,那么他的utf-8的编码第一位是0,后7位是65,即01000001,
对于“一”来说,用utf-8编码需要3个字节,那么第一个字节中前三位都是1,第四位0,后天每个字节前两位都是10,可以表示的utf-8位数是1110XXXX 10XXXXXX 10XXXXXX,此时X共有16位,正好是unicode编码需要的位数,用unicode编码填充X即可。
所以,A的utf-8编码仍是65,“一”的utf-8编码是:11100100 10111000 10000000
UTF-8/UTF-16/UTF-32
| 编码方式 | 码元 | 编码后字节数 |
|---|---|---|
| UTF-8 | 8位 | 1-4字节 |
| UTF-16 | 16位 | 2字节或者4字节 |
| UTF-32 | 32位 | 4字节 |
详见:
https://blog.csdn.net/weixin_41228949/article/details/122187108
https://blog.csdn.net/jimojianghu/article/details/125403110
http://t.zoukankan.com/kingyanan-p-9126115.html
各种协议属于什么层
链路层 :物理层面的,即驱动。
网络层 :TCP协议的X次握手,建立网络连接,这个过程算网络层。
传输层 :IP协议的拆包组包方面的验证,这个过程算传输层。
应用层 :传输信息内容的协议,比如HTTP、MQTT、COAP。
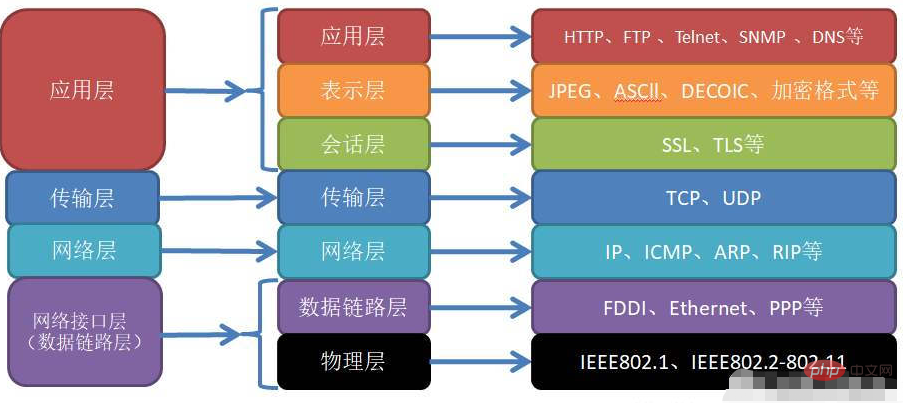
物联网方向的各种协议:
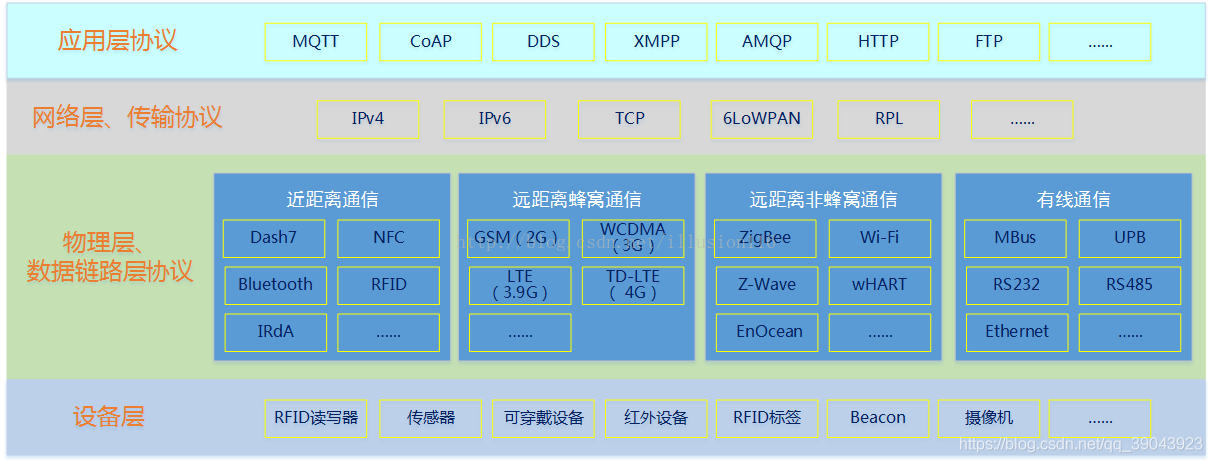
详见:https://blog.csdn.net/qq_39043923/article/details/90475226
https://blog.csdn.net/feiyanaffection/article/details/124479550
协议栈
NB-Iot网络协议栈
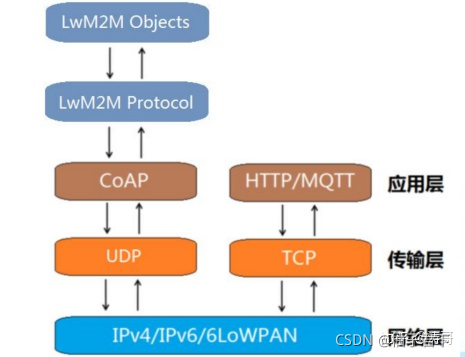
详见:https://blog.csdn.net/weixin_43662090/article/details/120515121
HTTP协议栈

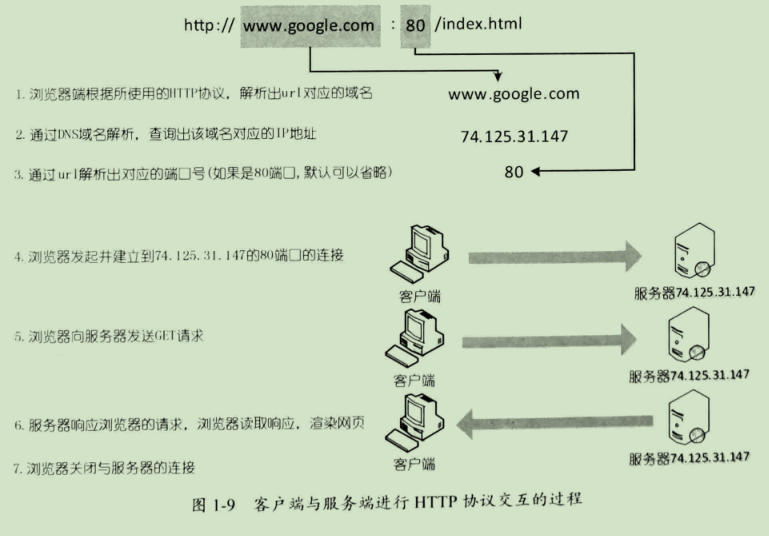
详见:https://www.cnblogs.com/zqfdgzrc/articles/10488101.html
协议涉及的方面
一款协议可能需要考虑的方方面面。
- 连接(网络)
- 传输
- 安全
- 内容
外设
GPIO,I2C,SPI,UART,USART,USB等通信方式/硬件接口的区别
【整理】嵌入式系统的各种常见外设
