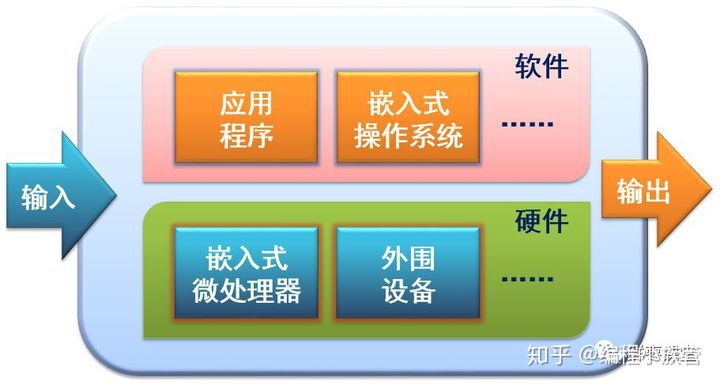
人工智能芯片分类、区别,以及发展途径和未来展望
本文转自:https://zhuanlan.zhihu.com/p/69629862
芯片的概念:(半导体元件产品的统称)集成电路,缩写作 IC;或称微电路、微芯片、晶片/芯片,在电子学中是一种把电路(主要包括半导体设备,也包括被动组件等)小型化的方式,并时常制造在半导体晶圆表面上。
专业地讲就是:将电路制造在半导体芯片表面上的集成电路又称薄膜(thin-film)集成电路。另有一种厚膜(thick-film)集成电路(hybrid integrated circuit)是由独立半导体设备和被动组件,集成到衬底或线路板所构成的小型化电路。
人工智能(Artificial Intelligence,AI)芯片的定义:从广义上讲只要能够运行人工智能算法的芯片都叫作 AI 芯片。但是通常意义上的 AI 芯片指的是针对人工智能算法做了特殊加速设计的芯片,现阶段,这些人工智能算法一般以深度学习算法为主,也可以包括其它机器学习算法。
AI芯片也被称为AI加速器或计算卡,即专门用于处理人工智能应用中的大量计算任务的模块(其他非计算任务仍由CPU负责)。当前,AI芯片主要分为GPU、FPGA、ASIC。
人工智能芯片四大类(按技术架构分类):
1、通用芯片(GPU)。
GPU是单指令、多数据处理,采用数量众多的计算单元和超长的流水线,主要处理图像领域的运算加速。
GPU是不能单独使用的,它只是处理大数据计算时的能手,必须由CPU进行调用,下达指令才能工作。
但CPU可单独作用,处理复杂的逻辑运算和不同的数据类型,但当需要处理大数据计算时,则可调用GPU进行并行计算。
2、半定制化芯片(FPGA)。
FPGA适用于多指令,单数据流的分析,与GPU相反,因此常用于预测阶段,如云端。FPGA是用硬件实现软件算法,因此在实现复杂算法方面有一定的难度,缺点是价格比较高。与 GPU 不同,FPGA 同时拥有硬件流水线并行和数据并行处理能力,适用于以硬件流水线方式处理一条数据,且整数运算性能更高,因此常用于深度学习算法中的推断阶段。不过FPGA 通过硬件的配置实现软件算法,因此在实现复杂算法方面有一定的难度。将FPGA 和 CPU 对比可以发现两个特点,一是 FPGA 没有内存和控制所带来的存储和读取部 分速度更快,二是 FPGA 没有读取指令操作,所以功耗更低。劣势是价格比较高、编程复杂、整体运算能力不是很高。目前国内的AI 芯片公司如深鉴科技就提供基于 FPGA 的解决方案。
3、全定制化芯片(ASIC)。
ASIC是为实现特定场景应用要求时,而定制的专用AI芯片。除了不能扩展以外,在功耗、可靠性、体积方面都有优势,尤其在高性能、低功耗的移动设备端。
定制的特性有助于提高 ASIC 的性能功耗比,缺点是电路设计需要定制,相对开发周期长,功能难以扩展。但在功耗、可靠性、集成度等方面都有优势,尤其在要求高性能、低功耗的移动应用端体现明显。谷歌的 TPU、 寒武纪的 GPU,地平线的 BPU都属于 ASIC芯片。谷歌的 TPU比 CPU和 GPU的方案快 30 至 80 倍,与 CPU和 GPU相比,TPU把控制电路进行了简化,因此减少了芯片的面积,降低了功耗。
4、类脑芯片。
类脑芯片架构是一款模拟人脑的神经网络模型的新型芯片编程架构,这一系统可以模拟人脑功能进行感知方式、行为方式和思维方式。
有人说,ASIC是人工智能芯片的一个主要发展方向,但真正的人工智能芯片未来发展的方向是类脑芯片。
类脑芯片研究是非常艰难的,IBM、高通、英特尔等公司的芯片策略都是用硬件来模仿人脑的神经突触。
AI 芯片按功能分类 :
根据机器学习算法步骤,可分为训练(training)和推断(inference)两个环节:
训练环节通常需要通过大量的数据输入,训练出一个复杂的深度神经网络模型。训练过程由于涉及海量的训练数据和复杂的深度神经网络结构,运算量巨大,需要庞大的计算规模,对于处理器的计算能力、精度、可扩展性等性能要求很高。目前市场上通常使用英伟达的GPU集群来完成,Google的 TPU2.0/3.0也支持训练环节的深度网络加速。
推断环节是指利用训练好的模型,使用新的数据去“推断”出各种结论。这个环节的
计算量相对训练环节少很多,但仍然会涉及到大量的矩阵运算。
在推断环节中,除了使用CPU或 GPU进行运算外,FPGA以及 ASIC均能发挥重大作用。
AI芯片的比较:
GPU未来的应用方向是高级复杂算法和通用性人工智能平台,买来就能使用。
FPGA更适用于各种具体的行业,人工智能会应用到各个具体领域。
ASIC芯片是全定制芯片。因为算法复杂度越强,越需要一套专用的芯片架构与其进行对应。定制就是当客户处在某一特殊场景时,可以为其独立设计一套专业智能算法软件。
而ASIC基于人工智能算法进行独立定制,其发展前景看好。
类脑芯片是人工智能最终的发展模式,但是离产业化还很遥远。
深度学习芯片使用情况比较:
⚫ CPU通用性最强,但延迟严重,散热高,效率最低。
⚫ GPU 通用性强、速度快、效率高,特别适合用在深度学习训练方面,但是性能功耗比较低。
⚫ FPGA具有低能耗、高性能以及可编程等特性,相对于 CPU与 GPU有明显的性能或者能耗优势,但对使用者要求高。
⚫ ASIC 可以更有针对性地进行硬件层次的优化,从而获得更好的性能、功耗比。但是 ASIC 芯片的设计和制造需要大量的资金、较长的研发周期和工程周期,而且深度学习算法仍在快速发展,若深度学习算法发生大的变化,FPGA 能很快改变架构,适应最新的变化,ASIC类芯片一旦定制则难于进行修改。
当前阶段,GPU 配合 CPU 仍然是 AI 芯片的主流,而后随着视觉、语音、深度学习的 算法在FPGA以及ASIC芯片上的不断优化,此两者也将逐步占有更多的市场份额,从而与 GPU达成长期共存的局面。从长远看,人工智能类脑神经芯片是发展的路径和方向。
人工智能芯片目前有两种发展路径:
一种是延续传统计算架构,加速硬件计算能力,主要以 3 种类型的芯片为代表,即 GPU、FPGA、ASIC, 但CPU依旧发挥着不可替代的作用;另一种是颠覆经典的冯·诺依曼计算架构,采用类脑神 经结构来提升计算能力,以 IBM TrueNorth 芯片为代表。
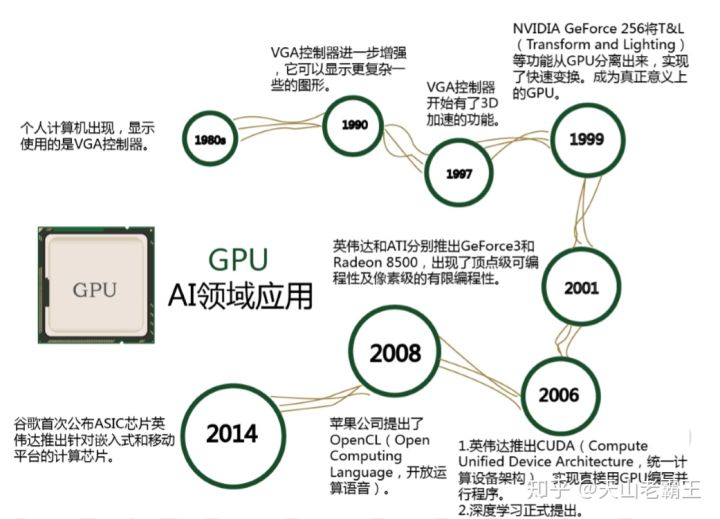 GPU芯片发展历程
GPU芯片发展历程
AI芯片与以往的普通芯片有什么区别呢?
手机AI芯片对于各种AI算子能够以30倍到50倍左右的速度处理。以拍照场景为例,AI芯片能够做更好的一个图像检测,图像分割和图像语义理解。另外,对声音可以听清、听懂,并根据所了解的客户意图提供客户真正想要的服务。比如,内置独立神经网络单元NPU的麒麟970的图片处理速度可达到约2005张每分钟,而在没有NPU的情况下每分钟只能处理97张图像。当然,其他应用场景在AI的加持下同样变得高能。
传统的 CPU及其局限性 :
计算机工业从 1960 年代早期开始使用 CPU 这个术语。迄今为止,CPU 从形态、设计到实现都已发生了巨大的变化,但是其基本工作原理却一直没有大的改变。通常 CPU 由控制器和运算器这两个主要部件组成。实质上仅单独的 ALU模块(逻辑运算单元)是用来完成数据计算的,其他各个模块的存在都是为了保证指令能够一条接一条的有序执行。这种通用性结构对于传统的编程计算模式非常适合,同时可以通过提升 CPU 主频(提升单位时间内执行指令的条数)来提升计算速度。但对于深度学习中的并不需要太多的程序指令、却需要海量数据运算的计算需求,这种结构就显得有些力不从心。尤其是在功耗限制下,无法通过无限制的提升CPU 和内存的工作频率来加快指令执行速度,这种情况导致CPU系统的发展遇到不可逾越的瓶颈。
并行加速计算的 GPU :
GPU作为最早从事并行加速计算的处理器,相比 CPU速度快,同时比其他加速器芯片编程灵活简单。
传统的CPU之所以不适合人工智能算法的执行,主要原因在于其计算指令遵循串行执行的方式,没能发挥出芯片的全部潜力。与之不同的是,GPU 具有高并行结构,在处理图形数据和复杂算法方面拥有比 CPU 更高的效率。对比 GPU 和 CPU 在结构上的差异,CPU 大部分面积为控制器和寄存器,而 GPU拥有更多的 ALU(ARITHMETIC LOGIC UNIT,逻辑运算单元)用于数据处理,这样的结构适合对密集型数据进行并行处理。程序在GPU系统上的运行速度相较于单核 CPU往往提升几十倍乃至上千倍。随着英伟达、AMD 等公司不断推进其对 GPU 大规模并行架构的支持,面向通用计算的 GPU(即 GPGPU,GENERAL PURPOSE GPU,通用计算图形处理器)已成为加速可并行应用程序的重要手段。
我国AI芯片发展情况 :
目前,我国的人工智能芯片行业发展尚处于起步阶段。
长期以来,中国在 CPU、GPU、DSP 处理器设计上一直处于追赶地位,绝大部分芯片设计企业依靠国外的 IP 核设计芯片,在自主创新上受到了极大的限制。然而,人工智能的兴起,无疑为中国在处理器领域实现弯道超车提供了绝佳的机遇。人工智能领域的应用目前还处于面向行业应用阶段,生态上尚未形成垄断,国产处理器厂商与国外竞争对手在人工智能这一全新赛场上处在同一起跑线上,因此,基于新兴技术和应用市场,中国在建立人工智能生态圈方面将大有可为。
由于我国特殊的环境和市场,国内 AI 芯片的发展目前呈现出百花齐放、百家争鸣的态势,AI 芯片的应用领域也遍布股票交易、金融、商品推荐、安防、早教机器人以及无人驾驶等众多领域,催生了大量的人工智能芯片创业公司,如地平线、深鉴科技、中科寒武纪等。尽管如此,国内公司却并未如国外大公司一样形成市场规模,反而出现各自为政的散裂发展现状。除了新兴创业公司,国内研究机构如北京大学、清华大学、中国科学院等在AI芯片领域都有深入研究;而其他公司如百度和比特大陆等,2017年也有一些成果发布。 可以预见,未来谁先在人工智能领域掌握了生态系统,谁就掌握住了这个产业的主动权。
展望未来:
目前主流 AI芯片的核心主要是利用 MAC(Multiplier and Accumulation,乘加计算)加速阵列来实现对 CNN(卷积神经网络)中最主要的卷积运算的加速。这一代 AI 芯片主要有如下 3个方面的问题。
(1)深度学习计算所需数据量巨大,造成内存带宽成为整个系统的瓶颈,即所谓的“memory wall”问题。
(2)与第一个问题相关,内存大量访问和MAC阵列的大量运算,造成AI芯片整体功耗的增加。
(3)深度学习对算力要求很高,要提升算力,最好的方法是做硬件加速,但是同时深度学习算法的发展也是日新月异,新的算法可能在已经固化的硬件加速器上无法得到很好的支持,即性能和灵活度之间的平衡问题。
因此,我们可以预见,下一代 AI芯片将有如下的几个发展趋势:
趋势一:更高效的大卷积解构/复用
在标准 SIMD 的基础上,CNN 由于其特殊的复用机制,可以进一步减少总线上的数据通信。而复用这一概念,在超大型神经网络中就显得格外重要。如何合理地分解、映射这些超大卷积到有效的硬件上成为了一个值得研究的方向。
趋势二:更低的 Inference计算/存储位宽
AI 芯片最大的演进方向之一可能就是神经网络参数/计算位宽的迅速减少——从 32 位浮点到 16 位浮点/定点、8 位定点,甚至是 4 位定点。在理论计算领域,2 位甚至 1 位参数位宽,都已经逐渐进入实践领域。
趋势三:更多样的存储器定制设计
当计算部件不再成为神经网络加速器的设计瓶颈时,如何减少存储器的访问延时将会成为下一个研究方向。通常,离计算越近的存储器速度越快,每字节的成本也越高,同时容量也越受限,因此新型的存储结构也将应运而生。
趋势四:更稀疏的大规模向量实现
神经网络虽然大,但是,实际上有很多以零为输入的情况,此时稀疏计算可以高效的减少无用能效。来自哈佛大学的团队就该问题提出了优化的五级流水线结构, 在最后一级输出了触发信号。在Activation层后对下一次计算的必要性进行预先判断,如果发现这是一个稀疏节点,则触发 SKIP信号,避免乘法运算的功耗,以达到减少无用功耗的目的。
趋势五:计算和存储一体化
计算和存储一体化(process-in-memory)技术,其要点是通过使用新型非易失性存储 (如ReRAM)器件,在存储阵列里面加上神经网络计算功能,从而省去数据搬移操作,即实现了计算存储一体化的神经网络处理,在功耗性能方面可以获得显著提升。